
Easy Way to build Recommendation System using Collaborative Filtering—In Python–Part-1
A Collaborative filtering is a one of the technique used while building recommendation system, it does so by combining information about multiple users. Most popular website use this technique like Netflix, Amazon use it to recommend product that is close to user on the basis of user action such as likes, dislikes and rating.
Earlier I was reading a book called “Programming Collective Intelligence” which talks about machine learning. I will be taking code snippet from this book, so In this article I’ll be explaining about collaborative filtering, its concept, algorithm and finally we will be building simple recommendation system using collaborative filtering.
What is Collaborative Filtering?
By the name “collab” it means we are combining. In this case we combine multiple user information and filter out the items that from the group of user that has similar tastes to the user. In general it’s a technique for filtering an item, which a user might like on the basis of combined actions by group of similar user
Algorithmn and Concepts
Euclidean Distance Score
Euclidean Distance is a simple way to calculate similarity score, which takes items that users have rated in common and uses them as axes for a chart. As show in Figure 1.
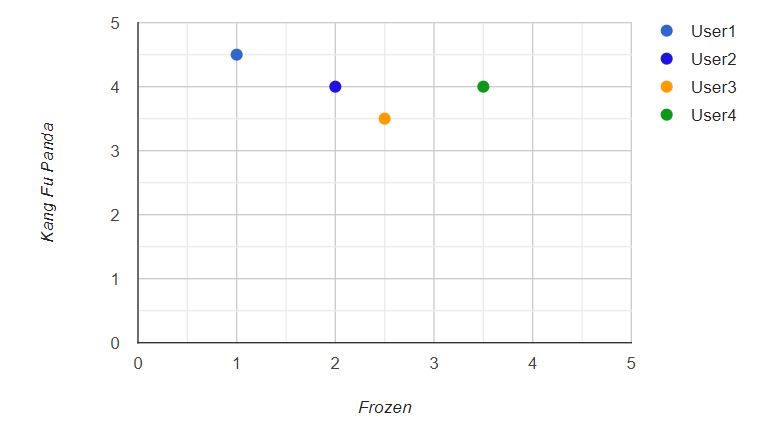
This figure shows the people charted in preference space. User1 has been plotted at 4.5 on the Kung Fu Panda axis and at 1.0 on the Frozen axis. The closer two people are in the preference space, the more similar their preferences are.
To calculate the distance between User1 and User2 in the chart, take the difference in each axis, square them and add them together, then take the square root of the sum. In Python, you can use the pow(n,2) function to square a number and take the square root with the sqrt function:
>> from math import sqrt
>> sqrt(pow(5-4,2)+pow(4-1,2))
3.1622776601683795
This formula calculates the distance, which will be smaller for people who are more similar. However, you need a function that gives higher values for people who are similar. This can be done by adding 1 to the function (so you don’t get a division-byzero error) and inverting it:
>> 1/(1+sqrt(pow(5-4,2)+pow(4-1,2)))
0.2402530733520421
This new function always returns a value between 0 and 1, where a value of 1 means that two people have identical preferences.
Example
Let’s say a person who has identical taste with other people is 1 and 0 for those who has no similar taste with other people, so our similarity value ranges from 0 to 1. Since we are combining people to find similarity among them and recommend a product depending on how similar they are. In order to measure similarity, I will be using Euclidean Distance Score in this article. There are many other measures depending on the problem you can chose other distance score measures. For this article I will be using movie lens dataset where you can find movie,user,rating.
- Step 1: Load the dataset
- Step 2: Calculate the similarity score between each user. If ‘user1’ is the one we are trying to recommend to then calcuate the similairy between ‘user1’ and all other users.
- Step 3: for every other user multiple each similarity we calculate in step 2 with the product rating that user has not rated before. In this case we will be multiplying other product which ‘user1’ has never rated before. It looks something like this in the figure below
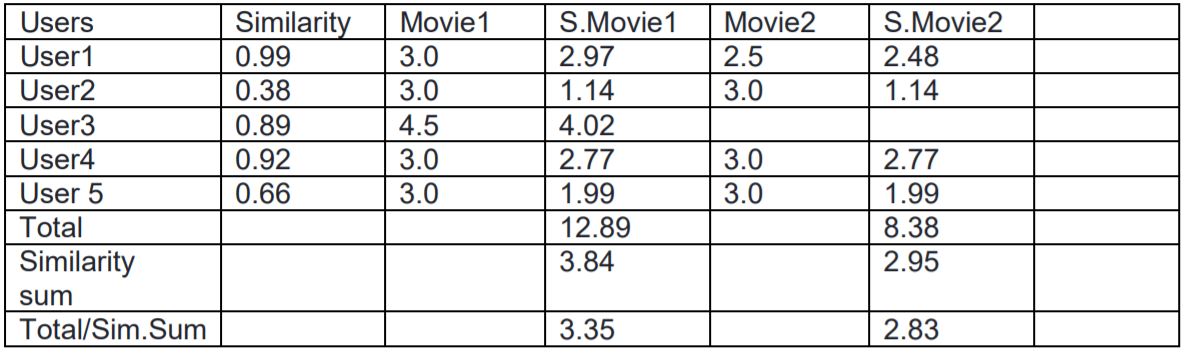
After multiplying similarity with each movie we calculate total of product of similarity and movie for each movie. Similarly we calculate sum of similarity of user who has rated movie. If you see blank in movie then its corresponding similarity value is not taken into consideration while calculating sum. Eg: In movie2 for user3 you can see blank so our similarity score for movie2 is 0.99+0.38+0.92+0.66 = 2.95. After calculating similarity we divide total/sim.sum and that value is the predicted score.
Pre-requisites
These are the following things you must do before getting started with implementation:
- Make sure you have python installed in your system
- You must have basic knowledge of python programming
- Make sure you have movie lens dataset downloaded you can find it on the internet
Implementation of the Algorithm
So far so good we have finished algorithm. Now Let’s make your had dirty using python. Create a file called recommendation.py. Inside this file we are going to add all code that will be mentioned here.
def loadMovieLens(path='/data/movielens'):
# Get movie titles
movies={}
for line in open(path+'/u.item'):
(id,title)=line.split('|')[0:2] movies[id]=title
# Load data
prefs={}
for line in open(path+'/u.data'):
(user,movieid,rating,ts)=line.split('\t') prefs.setdefault(user,{})
prefs[user][movies[movieid]]=float(rating)
return prefs
loadMovieLens() will load movielens data and return dictionary. Now we have loaded datset in the same file we will be calculating similary between users.
from math import sqrt
# Returns a distance-based similarity score for person1 and person2
def sim_distance(prefs,person1,person2):
# Get the list of shared_items
si={}
for item in prefs[person1]:
if item in prefs[person2]:
si[item]=1
# if they have no ratings in common, return 0
if len(si)==0: return 0
# Add up the squares of all the differences
sum_of_squares=sum([pow(prefs[person1][item]-prefs[person2][item],2) for item in prefs[person1] if item in prefs[person2]])
return 1/(1+sum_of_squares)
After calling sim_distance() it will calculate similarity score between users.
# Returns the best matches for person from the prefs dictionary.
def topMatches(prefs,person,n=5,similarity=sim_pearson):
scores=[(similarity(prefs,person,other),other)
for other in prefs if other!=person]
# Sort the list so the highest scores appear at the top
scores.sort( )
scores.reverse( )
return scores[0:n]
After calculating similar distance socre topMatches() ranks them in descending order that way we get highest rated similar users at first.Now the last part is getting recommendations.
def getRecommendations(prefs,person,similarity=sim_pearson):
totals={}
simSums={}
for other in prefs:
# don't compare me to myself
if other==person: continue
sim=similarity(prefs,person,other)
# ignore scores of zero or lower
if sim<=0: continue
for item in prefs[other]:
# only score movies I haven't seen yet
if item not in prefs[person] or prefs[person][item]==0:
# Similarity * Score
totals.setdefault(item,0)
totals[item]+=prefs[other][item]*sim
# Sum of similarities
simSums.setdefault(item,0)
simSums[item]+=sim
# print(totals)
# print(simSums)
# Create the normalized list
rankings=[(total/simSums[item],item) for item,total in totals.items()]
# Return the sorted list
rankings.sort( )
rankings.reverse( )
return rankings
getRecommendations() will give you recommendation for particular user. We can get recommendation by first loading dataset and then calling recommendation in the same file below.
prefs=loadMovieLens()
print("Recommended movies are ",getRecommendations(prefs,'27')) # 27 is user id corresponds to user name like “Alice” or “Bob”
By calling above two function you will get recommations in the form of list.
$ python3 recommendation.py
Recommended movies are [(5.0,'Superman returns'),..]
And that’s it we have created a recommendation system using Collaborative Filtering
Conclusion
Collabarative filtering is useful when your dataset is small and keeps on changing. But it does have some disadvantages like its computation time is significantly slower when your dataset increases. So depending on the problem we can use this technique to recommend product to users
Leave a comment